How can we take advantage from the information coming from the analysis side in order to synthesize a suitable expressive content?
A main research issue in the MEGA project is the study of the mapping strategies
of the recognized expressive content onto multimodal outputs, i.e. the exploration
about how the recognized expressiveness can influence the generation of multimodal
(sound, music, lights, movements, visual media) outputs.
Experiments start from immediate cause-effect relations to move toward long-term
complex mapping including dynamic moulding of the environment and expressive
multimodal gesture of character and avatars.
The following figures show two examples employed in the MEGA
performances in years 2 and 3.
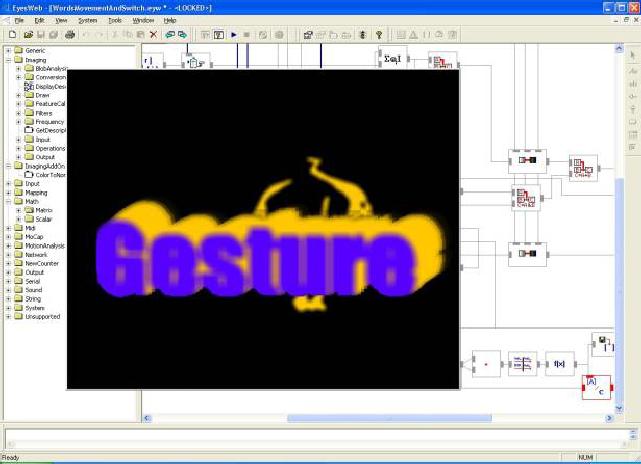
The first one shows deformations of an image depending on expressive audio and
motion cues. A lens metaphor is used. Different kinds of deforming lenses are
available in EyesWeb. The amount of deformation is related to values of the
extracted cues (e.g., Quantity of Motion, Contraction Index.) The dancerĺs
body, the background or both of them can be deformed. For example, in the left
image the background is deformed. The dancerĺs body is instead deformed in
the image on the right. The background bitmap can be selected by the artist
and can be dynamically changed during the performance.
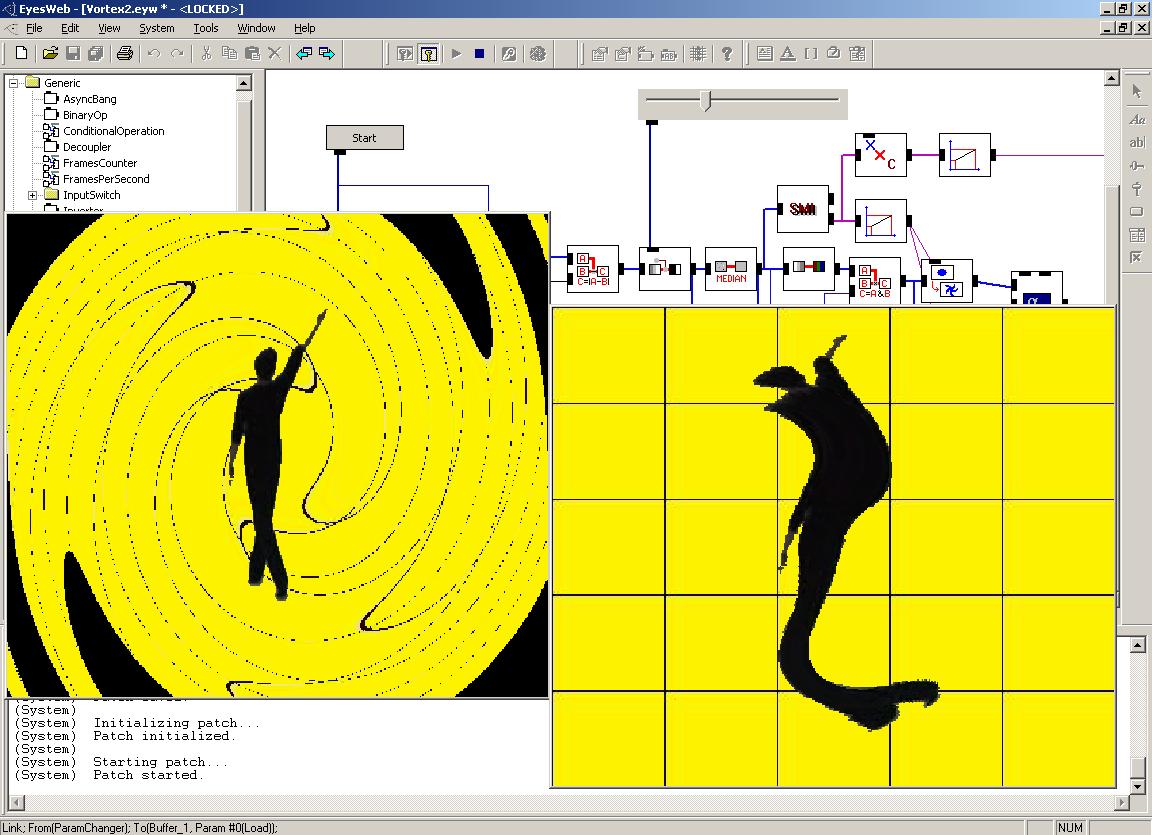
In the EyesWeb patch displayed in the figure here below the word ôGestureö is processed in real-time and moved on the screen depending on the motion cues extracted during a dance performance (the processed silhouette of the dancer is also shown in the output image). Several motion cues are used: for example, overall motion direction is used to control the motion of the word on the screen, Quantity of Motion is mapped on the color of the word, movement is segmented in pause and motion phases and the actual phase is used to switch among two different words: thus, the word ôExpressiveö is displayed during pauses, while the word ôGestureö is displayed when the dancer is moving. The amount of shadow and its color, both of the word and of the dancerĺs silhouette can also change in real-time depending on motion and audio cues.